
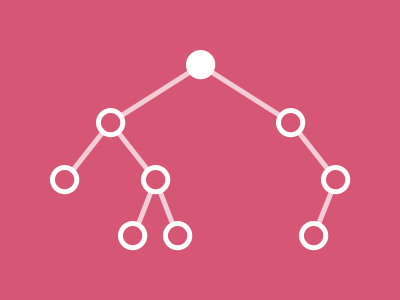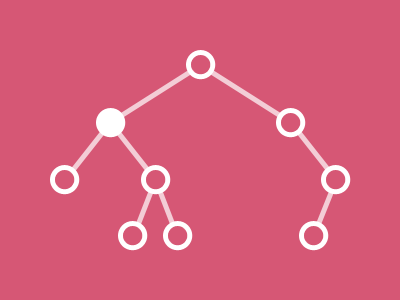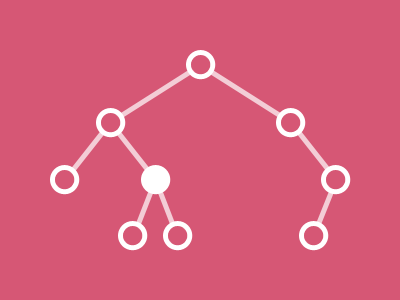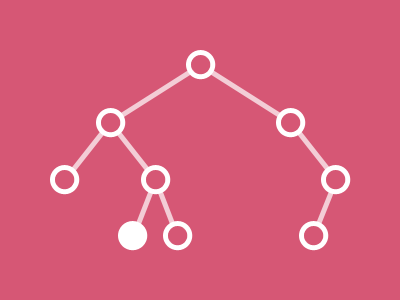
Comment visualiser l’algorithme de recherche d’un élément dans un arbre binaire (AB) ?
Python : Vérifiez si la variable est un dictionnaire
Comment visualiser l’algorithme d’effacement d’un élément dans un arbre binaire de recherche (ABR) ?
Python – Comment convertir une liste en dictionnaire ?
À partir d’une liste, comment écrire un programme en Python pour convertir la liste donnée en dictionnaire de sorte que tous les éléments impairs aient la clé et que les éléments pairs aient la valeur. Comme le dictionnaire python n’est pas ordonné, la sortie peut être dans n’importe quel ordre.
Exemples :
Input : ['a', 1, 'b', 2, 'c', 3]
Output : {'a': 1, 'b': 2, 'c': 3}
Input : ['Paris', 71, 'Rouen', 42]
Output : {'Paris': 71, 'Rouen': 42}
Méthode n°1 : compréhension de liste
Pour convertir une liste en dictionnaire, on peut utiliser la compréhension de liste et faire une paire clé:valeur d’éléments consécutifs. Enfin, on peut taper la liste en dict type.
def Convert(lst): res_dct = {lst[i]: lst[i + 1] for i in range(0, len(lst), 2)} return res_dct lst = ['a', 1, 'b', 2, 'c', 3] print(Convert(lst))
Output
{'a': 1, 'b': 2, 'c': 3}
Pour un aperçu, 👉 cliquez sur une couverture pour feuilleter le livre sur Amazon 📚.



Méthode n°2 : Utilisation de la méthode zip()
Créez d’abord un itérateur et initialisez-le à la variable “it”. Ensuite, utilisez la méthode du zip, pour zipper les clés et les valeurs ensemble. Enfin, vous pouvez le transformer en type dict.
def Convert(a): it = iter(a) res_dct = dict(zip(it, it)) return res_dct lst = ['a', 1, 'b', 2, 'c', 3] print(Convert(lst))
Output
{'a': 1, 'b': 2, 'c': 3}









Comment visualiser l’algorithme de recherche d’un élément dans un arbre binaire (AB) ?
Comment visualiser l’algorithme d’effacement d’un élément dans un arbre binaire de recherche (ABR) ?
Comment visualiser les parcours d’un arbre binaire de recherche (ABR) ?
Comment visualiser l’algorithme d’insertion d’un élément dans un arbre binaire de recherche (ABR) ?
Différence entre récursion et itération
Un programme est dit récursif lorsqu’une entité s’appelle elle-même. Un programme est appelé itératif lorsqu’il y a une boucle (ou répétition).
Exemple : Programme pour trouver la factorielle d’un nombre
Vous trouverez ci-dessous des explications détaillées pour illustrer la différence entre les deux :
Pour un aperçu, 👉 cliquez sur une couverture pour feuilleter le livre sur Amazon 📚.
1 – Complexité du temps : Trouver la complexité temporelle de la récursion est plus difficile que celle de l’itération.
- Récursion : La complexité temporelle de la récursivité peut être trouvée en trouvant la valeur du n-ième appel récursif par rapport aux appels précédents. Ainsi, trouver le cas de destination en termes de cas de base, et le résoudre en termes de cas de base nous donne une idée de la complexité temporelle des équations récursives.
- Itération : La complexité temporelle de l’itération peut être trouvée en trouvant le nombre de cycles qui se répètent à l’intérieur de la boucle.
2 – Utilisation : L’utilisation de l’une ou l’autre de ces techniques est un compromis entre la complexité temporelle et la taille du code. Si la complexité temporelle est le point central, et que le nombre d’appels récursifs est important, il est préférable d’utiliser l’itération. Cependant, si la complexité temporelle n’est pas un problème et que la taille du code l’est, la récursivité serait la solution.
- Récursion : La récursivité consiste à appeler la même fonction à nouveau, et donc, a une très petite longueur de code. Cependant, comme nous l’avons vu dans l’analyse, la complexité temporelle de la récursion peut devenir exponentielle lorsqu’il y a un nombre considérable d’appels récursifs. Par conséquent, l’utilisation de la récursion est avantageuse dans le cas d’un code plus court, mais d’une complexité temporelle plus élevée.
Itération : L’itération est la répétition d’un bloc de code. Cela implique une plus grande taille de code, mais la complexité temporelle est généralement moindre que pour la récursivité.
3 – Répétition infinie : La répétition infinie en récursion peut entraîner un crash du processeur mais en itération, elle s’arrête lorsque la mémoire est épuisée.
- Récursion : Dans la récursion, des appels récursifs infinis peuvent se produire en raison d’une erreur de spécification de la condition de base, qui, ne devenant jamais fausse, continue d’appeler la fonction, ce qui peut entraîner un crash du CPU du système.
- Itération : L’itération infinie due à une erreur dans l’affectation ou l’incrémentation de l’itérateur, ou dans la condition de fin, conduira à des boucles infinies, qui peuvent ou non conduire à des erreurs système, mais arrêteront sûrement l’exécution du programme plus loin.
| PROPRIÉTÉ | RÉCURSION | ITÉRATION |
|---|---|---|
| Définition | La fonction s’appelle elle-même. | Un ensemble d’instructions exécutées de manière répétitive. |
| Application | Pour les fonctions. | Pour les boucles. |
| Terminaison | Par le cas de base, où il n’y aura pas d’appel de fonction. | Lorsque la condition de sortie de l’itérateur cesse d’être remplie. |
| Utilisation | Utilisé lorsque la taille du code doit être petite et que la complexité du temps ne pose pas de problème. | Utilisé lorsque la complexité temporelle doit être compensée par une taille de code plus importante. |
| Taille du code | Taille du code plus petite | Taille du code plus grande. |
| Complexité temporelle | Très grande (généralement exponentielle) complexité temporelle. | Complexité temporelle relativement plus faible (généralement polynomiale et logarithmique). |






